Что сие означает
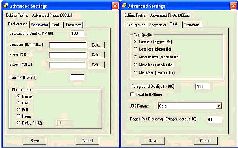
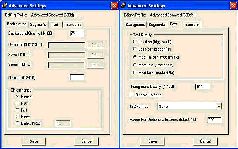
На вкладках тонкой настройки профилей основное место занимают опции кодера – коэффициент усиления, обработка полутонов и яркостной составляющей и т. п. Трогать эти настройки нужно только в том случае, если требуется специальным образом закодировать сложное и объемное изображение. В случае книжных сканов в этом нет никакой необходимости, так что интерес будут представлять только группа параметров Text Quality, список JB2 Format, цифровое поле Pages per Dictionary и поля Back/Foreground Quality.
Группа Text Quality задает методику кодирования контрастных контуров, опознанных по единообразию размеров (т. е. представляющих символы шрифта). Значения в этом списке можно менять только для профилей Scanned и Photo (в профиле Bitonal изменение установки качества на любую, кроме Most-loss (~aggressive) приводит к конфликту при работе кодировщика). На размер файла эти настройки влияют довольно слабо (для серых сканов и изображений размер меняется в пределах 20 % при установках от Lossless до Most-Loss).
Поля Background Quality и Foreground Quality выставляют фактор сжатия JBIG соответственно для слоев заднего и переднего планов. На размер выходного файла влияют слабо, если только скан не снят с формата A3. В принципе, значения, показанные на рисунках, дают оптимальное качество в подавляющем большинстве случаев книгосканирования.
Поле Pages per Dictionary – именно та настройка, наличие которой позволяет существенно сократить размер файла. Она задает максимальное количество страниц, на которые будет распространяться отдельный словарь. Это позволяет (за счет единообразия типографского шрифта) увеличить степень сжатия в несколько раз. В то же время, задавать большое количество страниц на словарь для профилей Photo и Scanned нецелесообразно – что приведет к ухудшению качества.
После того, как все настройки заданы, можно сохранить профили (дав им информативные имена, вроде
Для начала нужно рассортировать выходные файлы на несколько групп, каждую из которых будет кодировать свой профиль. В отдельные группы выделяем: файлы с текстом и диффузными черно-белыми иллюстрациями, текстом и черно-белыми недиффузными иллюстрациями, цветные и черно-белые вклейки.
Собственно, профиль Scanned нужен только для самых сложных случаев (страницы с текстом и высококонтрастными черно-белыми клишированными фотографиями, не поддающимися диффузному кодированию), основную работу сделают профили Bitonal и Photo. Группы файлов можно разобрать по папкам с именами профилей, чтобы потом не ошибаться с выбором. Затем запускаем приложение Workflow Manager пакета Document Express Enterprise.
Командой меню File =› Open Image… открываем первые из подлежащих кодированию файлов (но не обложку!). Как правило, первые страницы книги целиком черно-белые. Для них подойдет профиль на основе Bitonal. Смотря по характеру страниц, можно выбрать и другой профиль. Открыв изображение, выбираем для кодирования ранее подготовленный профиль из списка Raster Profile.
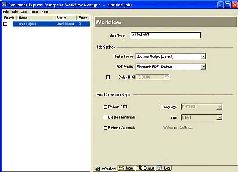
Если книга не имеет иллюстраций в тексте, все страницы, кроме обложек, можно сразу сохранить в один DjVu-файл. Если же имеются иллюстрации, цветные вклейки и т. п., то каждую страницу нужно сохранить в свой DjVu-файл, чтобы потом собрать их воедино в редакторе. Обычно, кодируя книгу, я заранее сохраняю первые страницы без иллюстраций в один DjVu-файл с именем, совпадающим с именем книги (соответственно, эти файлы уже не выделяю ни в какую группу для кодирования). Потом в папку, где лежит этот файл, кодирую все оставшиеся страницы – каждую в отдельный файл. Открыв затем редактором файл с именем «Название книги. djvu», просто добавляю к нему уже имеющиеся закодированные DjVu- файлы, предварительно отсортировав их по именам. Так легко и быстро можно получить готовый файл для добавления обложек.
Итак, открыв изображения, подлежащие кодированию тем или иным профилем, задаем в поле Job Name имя задания. Если книга сохраняется в один файл, то эта строка будет его именем. В противном случае все файлы DjVu, соответствующие страницам, будут сохранены с именами, совпадающими с именами файлов страниц.
Теперь время перейти с вкладки Workflow на вкладку Output. Здесь из списка Separate Files выбираем тип сохранения: One document only (единичный документ), либо Each file (каждый файл отдельно). Затем, щелкнув по ссылке Choose Folder… выбираем папку для сохранения выходных файлов DjVu. Если сохранение идет по одному файлу, крайне нежелательно сохранять DjVu-страницы в папку с выходными файлами ScanKromsator (папку с изображениями страниц) это очень затруднит выбор файлов для открытия редактором.

Каждая команда Open Images… (кроме первой после запуска программы) в Workflow Manager создает новое задание (
Когда готов весь набор файлов DjVu (книга в одном файле или в виде страниц, обложки), можно сложить все файлы в одну папку, и приступить к сборке полноценной электронной книги. Запускаем Document Express Editor.

Открываем в Document Express Editor файл с первой страницей обложки.
Затем командами меню Edit =› Insert Page(s)… добавляем в нужные места все остальные подготовленные файлы. Теперь книга имеет законченный вид, и ее можно сохранить командой File =› Save As…
Остались сущие пустяки – добавить в книгу текст, распознанный в FineReader, и создать оглавление. Начнем с добавления текста. Находим в редакторе страницу, с которой начиналось распознавание и запоминаем ее номер (теперь он не первый, как это было в пакете FineReader, так как добавились обложка и форзац). Теперь закроем редактор, и запускаем приложение DjVuOCR 2.4 (автор – камрад Gencho из солнечной Болгарии).

Интерфейс этого процессора обработки DjVu интуитивно понятен. Нас интересует режим «Ручной OCR manager». Здесь нужно указать адрес папки пакета FineReader с распознанной книгой, номер первой страницы пакета в файле DjVu, а также имя самого файла DjVu. Флажок «Создать» не должен пугать – на