удаляется из базы и в нее добавляется новый фрагмент Fr2. Или если в базе знаний обнаружен фрагмент Fr1, то в решателе утверждению, описываемому фрагментом Fr2, приписывается значение «истина». Возможны и иные варианты. Пусть для определенности тип продукции таков, что она описывает поиск в базе знаний некоторого фрагмента Fr1 и при обнаружении его исключает соответствующую информацию из базы, добавляя в нее информацию, описанную в Fr2.

Рис. 34.
На рис. 34 показана такая продукция. Знак вопроса означает, что в качестве имени вершины может выступать любое из тех, которые имеются в базе знаний. Но если знак вопроса заменен какой-то вершиной, то в правой части продукции появляется такое же имя. Исходное состояние базы знаний показано на рис. 35, а. Для облегчения дальнейших рассуждений будем считать, что вершины семантической сети соответствуют некоторым персонажам, отношение R1 имеет смысл «быть отцом», отношение R2 – «быть матерью», а отношение R3 – «носить фамилию». Тогда продукция, показанная на рис. 34, может интерпретироваться следующим образом: «Если в базе знаний есть сведения о детях, для которых D является отцом, а К – матерью, то эту информацию из базы надо убрать, добавив в нее информацию о том, что все эти дети носят фамилию М».

Рис. 35.
Обработка продукции идет следующим образом. В семантической сети, показанной на рис. 35, а, ищутся вершины с именами D1 и К. Если таких вершин (или одной из них) в базе нет, то поиск прекращается и выдается сигнал о неудаче поиска. Если вершины найдены, то из вершины D возбуждаются все отношения с именем R1, а из вершины К – все отношения с именем R2. Так возникают две волны возбуждения. Первая волна возбуждает вершины С, F, G и H, а вторая – вершины F, G, Н и I. Волны встречаются лишь в вершинах F, G и H. В вершинах C и I возбуждение угасает. На замещение знака «?» в продукции претендуют вершины с именами F, G и H. Эти же имена возникают в правой стороне продукции. На рис. 35, б показано результирующее состояние базы знаний после того, как продукция завершила свою работу.
В более сложно организованных образцах для поиска могут присутствовать условия применимости продукций, о которых говорилось при обсуждении общей формы продукции. Например, образец мог бы иметь вид «Если имеет место Fr1, то Fr2, иначе Fr3». Образцы такого типа задают альтернативные выводы в базах знаний. О них упоминалось в конце третьей главы.
Если при выводе на семантической сети фрагмент Fr2 добавляется в базу знаний без выбрасывания Fr1, то говорят о процедурах пополнения знаний. Человек в своей жизнедеятельности часто выполняет подобные процедуры, используя те знания о закономерностях внешнего мира, которые ему известны. Если, например, имеется текст «Поезд подошел к перрону. Через несколько минут Андрей уже обнимал Татьяну. Такси быстро домчало их до дома, и Татьяна почувствовала, что длительное путешествие ушло в прошлое», то человеку весьма нетрудно пополнить его событиями, которые в явном виде в этом тексте отсутствуют. Ясно, например, что между событием, описанным в первом предложении, и тем, которое зафиксировано как второе, имеется пропуск. Второе событие произойдет, если Андрей и Татьяна окажутся в одном месте. Один из них должен был войти в вагон или другой – выйти из вагона. (При чтении текста последовательно пока неясно, кто приехал и кто ожидал на перроне.) Поэтому восстановление пропущенных событий напоминает вывод с некоторыми оценками правдоподобия. Третье событие, зафиксированное в тексте, не может непосредственно следовать за вторым. Для его реализации надо, чтобы Андрей и Татьяна сели в такси, а если предположить, что Андрей обнимал Татьяну на перроне (что весьма правдоподобно), то надо было еще дойти до места посадки в такси. Наконец, четвертое событие, связанное с ощущением, охватившим Татьяну, увеличивает правдоподобность того, что из путешествия вернулась именно Татьяна, а не Андрей (хотя стопроцентно этого утверждать на основании текста нельзя). Кроме того, либо время четвертого события совпадает с временем третьего события, либо четвертое событие происходит позже третьего, когда Татьяна уже вышла из такси, а возможно, и вошла в свой дом.
Читатель должен почувствовать, что пополнение знаний – процедура весьма непростая. Приведенный простенький пример уже продемонстрировал необходимость в альтернативном выборе при пополнении, а также в правдоподобных рассуждениях.
Но самое главное – этот альтернативный выбор может оказаться источником всевозможных неверных выводов при дальнейшей работе с базой знаний.
Остановимся лишь на одном случае такой опасности, который среди специалистов по интеллектуальным системам получил название эффекта немонотонных рассуждений. Поясним его на популярном примере. До того, как европейцы узнали, что в Таиланде водятся белые слоны (так называемые королевские слоны), они были уверены, что все слоны серые. Это означало, что в модели знаний о слонах имел место фрагмент, показанный на рис. 36, а. В этом фрагменте R есть отношение, a Q – отношение «быть серого цвета». Если Тони – имя некоторого конкретного слона, то из информации, отраженной в данном фрагменте знаний, следует, что «Тони имеет серый цвет». Но при условии, что слон Клайд является королевским, для него такой вывод будет неверным. Это означает, что при появлении нового знания о том, что «Клайд – королевский слон», ранее сделанный относительно него вывод «Клайд имеет серый цвет» становится ложным. В этом и состоит немонотонность вывода.

Рис. 36.
В обычной логике вывод всегда бывает монотонным. Если из множества утверждений {Fi} следует утверждение F*, то как бы ни расширилось множество {Fi}, истинность утверждения F* не может измениться. А у нас имеется прямо противоположная ситуация. Появление нового утверждения «Клайд – королевский слон» отменяет истинность утверждения «Клайд имеет серый цвет».
На рис. 36, б показана семантическая сеть, в которой учтен новый факт, касающийся королевских слонов. Дуга 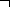 R соответствует отношению «не принадлежит к классу», а дуга Q’ – отношению «быть белого
R соответствует отношению «не принадлежит к классу», а дуга Q’ – отношению «быть белого