Элемент
Теги в XML-документе не просто размечают текст — они выделяют объект, который и называется
Элементы могут быть пустыми, то есть не содержать ни данных, ни других конструкций, либо непустыми — включать в себя текст, другие элементы и т.п.
Пустой элемент имеет следующий вид:
<
<img src='image.gif'/>
<br/>
<answer question='To be or not to be?' value='Perhaps'/>
Непустые элементы имеют вид:
<
...
...
</
<myelement myattribute='myvalue'>
<mysubnode>
sometext
</mysubnode>
</myelement>
И в том, и в другом случае, имя задает имя элемента, а конструкции вида MyElement, myelement и MYELEMENT различаются. Кроме того, имена в XML могут принадлежать различным
Элементы являются основной конструкцией языка XML. Организуя содержимое в элементах, можно явно выделить иерархическую структуру документа. Легко заметить, что документ, состоящий из вложенных друг в друга элементов, устроен подобно дереву: родительский элемент является корнем, в то время как дочерние элементы, которые включаются в него, являются ветками, а если они не содержат ничего более, то и листьями. Следующий пример (рис. 1.1) иллюстрирует эту концепцию.
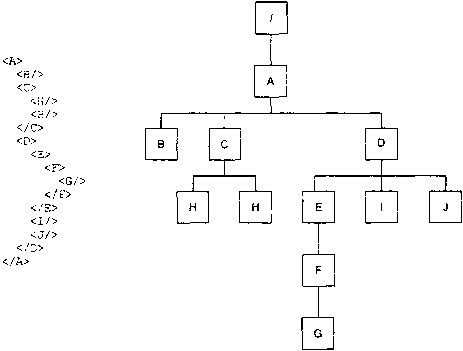
Рис. 1.1. Документ и соответствующее ему дерево элементов
Очень важно понять, что XML-документ логически организован в виде дерева. Дерево является довольно простой структурой для обработки, но при этом выразительная сложность его весьма велика. Древовидная структура является одной из наиболее подходящих абстракций для описания объектов и отношений в реальном мире — возможно именно древовидное устройство наряду с простотой использования обеспечили XML такой потрясающий успех.
Обратимся теперь к синтаксису элементов. EBNF-правило, определяющее элемент, выглядит следующим образом:
[39] element ::= EmptyElemTag
| STag content ETag
Пустому элементу соответствует нетерминал EmptyElemTag. Непустой элемент начинается открывающим тегом (нетерминал STag), включает некоторое содержимое (content) и заканчивается закрывающим тегом (ETag).
Открывающий тег состоит из имени (Name) и последовательности определений атрибутов (Attribute), которые разделены пробельными символами:
[40] STag ::= '<' Name (S Attribute)* S? '>'
В ряде случаев атрибуты тега могут отсутствовать.
Перед закрывающей угловой скобкой тега могут также стоять пробельные символы, поэтому вполне корректной будет следующая запись:
<а
href='http://www.xsltdev.ru'
>
В закрывающем теге имени предшествует косая черта ('/') и перед закрывающей угловой скобкой тоже могут стоять пробелы:
[42] ETag ::= '</' Name S? '>'
Имена в открывающем и закрывающем тегах должны совпадать.
Содержимое элемента может состоять из элементов (нетерминал element), сущностей (Reference), секций символьных данных (CDSect), инструкций по обработке (PI) и комментариев (Comment), перемешанных с символьными данными (CharData):
[43] content ::= CharData?
((element
| Reference
| CDSect
| PI
| Comment) CharData?)*
Пустой элемент не имеет содержимого и задается продукцией EmptyElemTag в следующем виде:
[44] EmptyElemTag ::= '<' Name (S Attribute)* S? '/>'
Тег пустого элемента выглядит точно так же, как и тег непустого элемента с той лишь разницей, что перед закрывающей угловой скобкой стоит символ косой черты ('/'). В этом, кстати, одно из главных отличий синтаксиса языка XML от HTML. Например, вместо <HR> в XML следует писать <HR/>.
Для того чтобы привести синтаксис HTML в соответствие со стандартом XML, был создан язык XHTML. Этот язык полностью соответствует синтаксису XML, что делает возможным обработку XHTML- документов XML-средствами, но при этом набор тегов XHTML идентичен набору тегов языка HTML. К сожалению, далеко не все браузеры поддерживают XHTML. Чаще всего проблемы возникают именно с пустыми элементами (или одиночными тегами в терминах HTML): например, браузеры могут некорректно воспринимать запись вида <br/>. В большинстве случаев проблема решается использованием перед косой чертой пробела: запись вида <br />, скорее всего, будет обработана корректно.