меньше
В таблице 2.4 сгенерированы коэффициенты уравнения регрессии и оценки их статистической значимости.
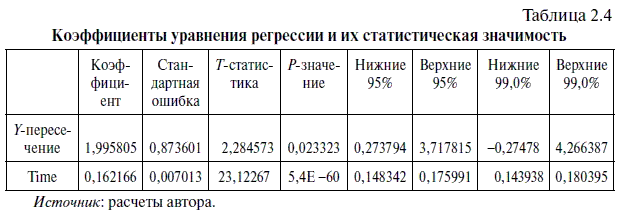
1. В столбце КОЭФФИЦИЕНТЫ представлены коэффициенты уравнения регрессии. На пересечении этого столбца со строкой
Во второй строке этого столбца, обозначенной как Time (независимая переменная — порядковый номер месяца), сгенерирован коэффициент уравнения регрессии, который в формуле (2.2) представлен символом
Таким образом, данные, представленные в столбце Коэффициенты, дают нам возможность составить путем подстановки соответствующих цифр в формулу (2.2) следующее уравнение линейной парной регрессии:
где независимая переменная
зависимая переменная
При этом экономическая интерпретация этого линейного уравнения следующая: в период с июня 1992 г. по апрель 2010 г. курс доллара к рублю ежемесячно рос со средней скоростью 16,22 коп. при исходном уровне временного ряда в размере 1 руб. 99,58 коп. В свою очередь геометрическая интерпретация этого линейного уравнения следующая: свободный член уравнения 1,9958 показывает точку пересечения линии тренда с осью
2. В столбце СТАНДАРТНАЯ ОШИБКА сгенерированы стандартные ошибки свободного члена и коэффициента регрессии, значения которых даны во втором столбце табл. 2.4. При этом стандартная ошибка свободного члена уравнения регрессии находится по следующей формуле:
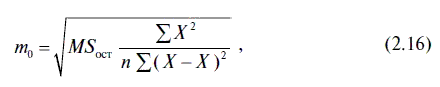
где
Для нашего случая стандартная ошибка свободного члена уравнения регрессии равна
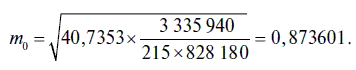
В свою очередь стандартная ошибка коэффициента регрессии оценивается по следующей формуле:

Для нашего случая стандартная ошибка коэффициента регрессии имеет следующее значение:
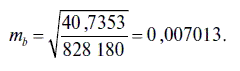
3. В столбце

где
В нашем случае
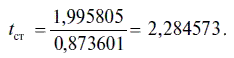
Для коэффициента регрессии

где
Тогда Z-статистика находится следующим образом:
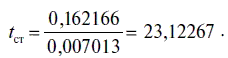
4. В столбце
В Excel
СТЬЮДРАСП
где в опции
в опции
Для свободного члена уравнения эта функция приобретает следующий вид:
СТЬЮДРАСП (2,284573; 215-1-1= 213; 2) = 0,023323.
Следовательно,
Для коэффициента регрессии P-значение в Excel находится следующим образом[4]:
СТЬЮДРАСП (23,12267; 215 — 1–1= 213; 2) = 5,4Е — 60 = 0,0.
Следовательно,
5. Столбцы НИЖНИЕ 95 % и ВЕРХНИЕ 95 % показывают соответственно нижние и верхние интервалы значений коэффициентов при 95 %-ном уровне значимости. Для расчета доверительных интервалов сначала устанавливается критическое значение /-критерия, которое в Excel находится с помощью функции
СТЬЮДРАСПОБР (? = 0,05;
где в опции ? — величина риска, при котором коэффициент регрессии (или свободный член) может оказаться за рамками установленных доверительных интервалов;
в опции
Таким образом, для 95 %-ного уровня надежности
Далее для свободного члена уравнения находим:
1. Значение столбца НИЖНИЕ 95 % = КОЭФФИЦИЕНТ — СТАНДАРТНАЯ ОШИБКА ?
2. Значение столбца ВЕРХНИЕ 95 % = КОЭФФИЦИЕНТ + СТАНДАРТНАЯ ОШИБКА ?
Для коэффициента регрессии TIME находим:
1. Значение столбца НИЖНИЕ 95 % = КОЭФФИЦИЕНТ — СТАНДАРТНАЯ ОШИБКА ?
2. Значение столбца ВЕРХНИЕ 95 % = КОЭФФИЦИЕНТ + СТАНДАРТНАЯ ОШИБКА ?
6. Столбцы НИЖНИЕ 99 % и ВЕРХНИЕ 99 % показывают соответственно нижние и верхние интервалы значений коэффициентов при 99 %-ном уровне значимости. При этом значения столбца НИЖНИЕ 99 % и ВЕРХНИЕ 99 % находятся аналогичным образом, как и значения столбцов НИЖНИЕ 95 % и ВЕРХНИЕ